Posts
Plotting Ideology vs Engagement
Introducing a new visualization in Members by Interest – scatter plots that show the relationship between a member’s engagement with a given topic (as measured by adjusted score) and their ideology (as measured by Dimension 1 DW-NOMINATE scores).
As noted before, adjusted scores measure a member’s interest in a given topic as reflected by those measures about that topic (as cataloged by the folks at LC) that they sponsor and cosponsor. These scores are the same ones that drive the existing visualizations where members are ranked by the intensity of their legislative interests. What’s new with visualization is the incorporation of DW-NOMINATE scores.
The Dynamic Weighted NOMINAl Three-step Estimation metric was pioneered by Keith T. Poole and Howard Rosenthal at Carnegie-Mellon University. The system they developed plots members along axes of “left” and “right” (the Dimension 1 used in this visualization) and other pressing issues of the day (Dimension 2). This plotting is based on comparing roll call votes to one another and is further described in Poole’s Spatial Models of Parliamentary Voting.
As with the ranked view, users can examine data for both Policy Areas and Legislative Subject Terms. Unlike the ranked view, users will be limited to viewing results for an individual congress (DW-NOMINATE scores for the same member may vary by congress).
Sometimes there are strong correlations between ideology and subject engagement, as with the Policy “Civil Rights and Liberties, Minority Issues”:
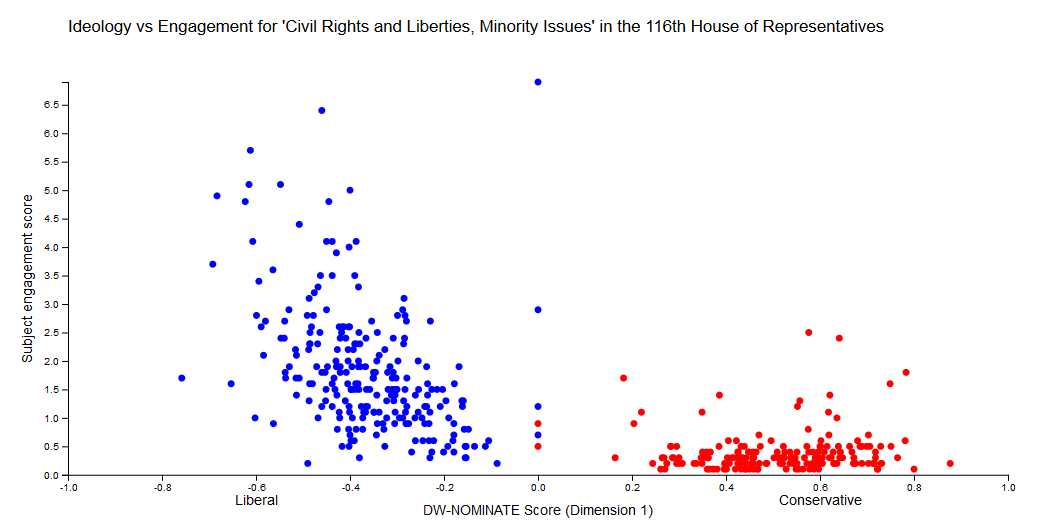
…or the Legislative Subject “Abortion”:
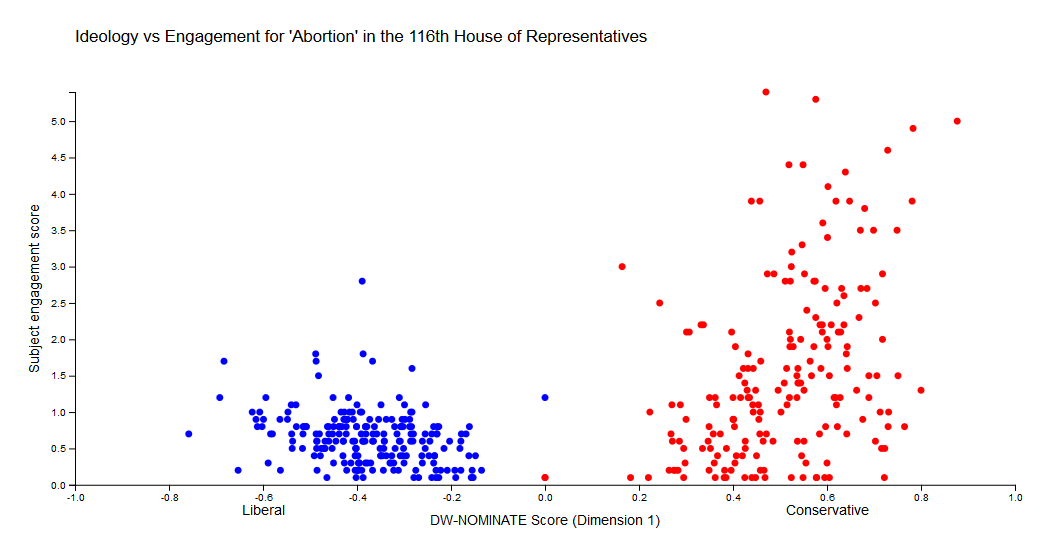
In other cases there seems to be little obvious relationship between engagement and ideology, as with “Native Americans”:
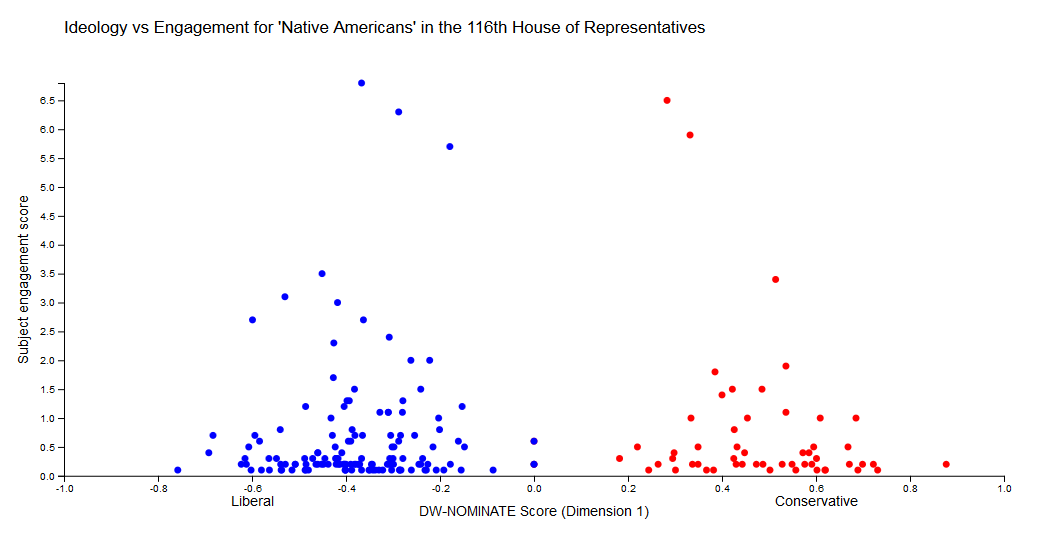
If you hover over a point, you see the member in question, as well as how many measures she has sponsored and cosponsored about that topic.
As always, contact me if you have any questions or suggestions.
– ❉ –
Changing the formula for Members by Interest
I’ve made a small but important change to Members by Interest. It currently uses an “adjusted score” when ranking a member’s interest in a given topic as reflected by those measures about that topic (as cataloged by the folks at LC) that they sponsor and cosponsor. Sponsoring a bill or resolution counts for three points, being an “original” cosponsor counts for two points and joining as a cosponsor after a measure has been introduced counts for just one. This is intended to account for the fact that it is more difficult to sponsor a bill than to cosponsor another’s, as well as the fact that an initial cosponsor may have had some input on a measure.
After living with this for a bit, I think this formula undervalues the difference in effort between sponsoring a bill (or resolution) and cosponsoring someone else’s measure. This is particularly true for broad Policy Areas such as “Health”, where it seems to me that Reps. DeLauro and Burgess are both a little further down on this list than they should be:

Therefore, I am introducing a new formula: sponsoring a bill or resolution now earns a member one point, being an original cosponsor is worth .2 points and .1 point is awarded for cosponsoring after a measure is introduced. With sponsorship “worth” five times as much as original cosponsorship (and ten times as much as sponsorship after introduction), this scale seems to do a better job of ranking members according to the intensity of their engagement:
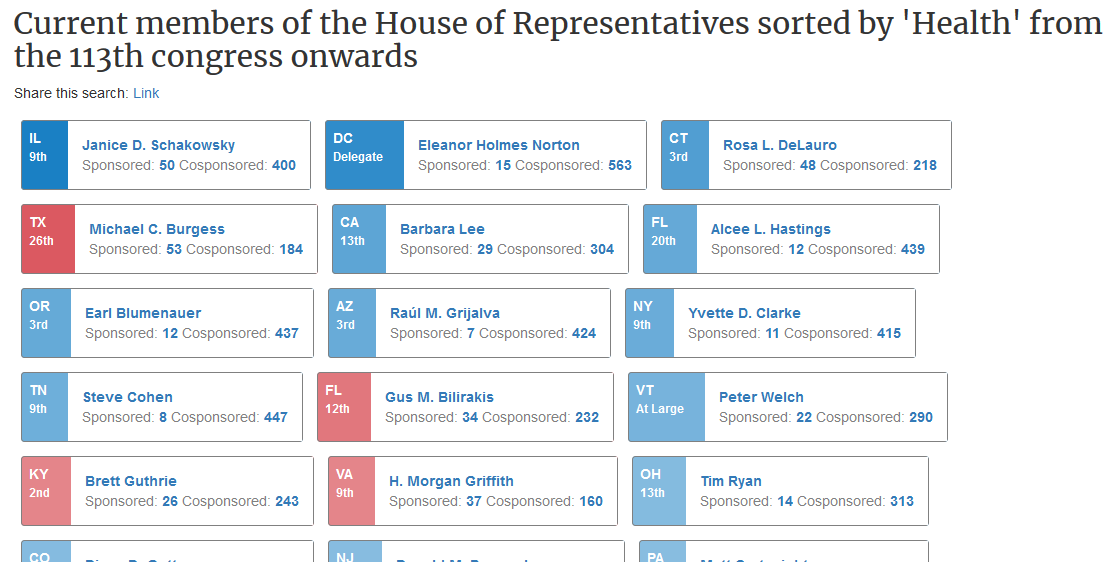
As before, the raw numbers of measures sponsored and cosponsored are listed below the member’s name, so you’re welcome to judge for yourself where they land on the list.
Importantly, this change in scoring pertains to the display of individual member’s interests as well. For example, this graph of interests for Sen. Baldwin:
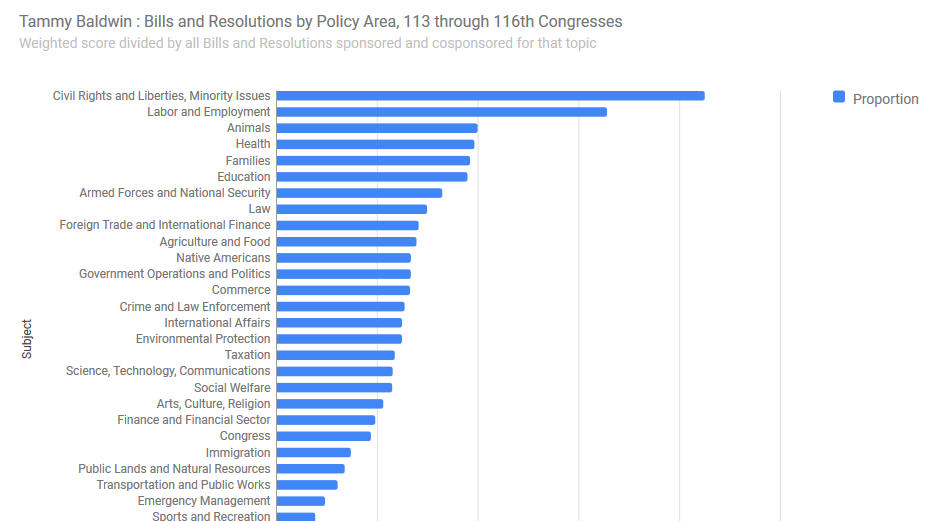
…becomes under the new formula something very similar, but slightly different:
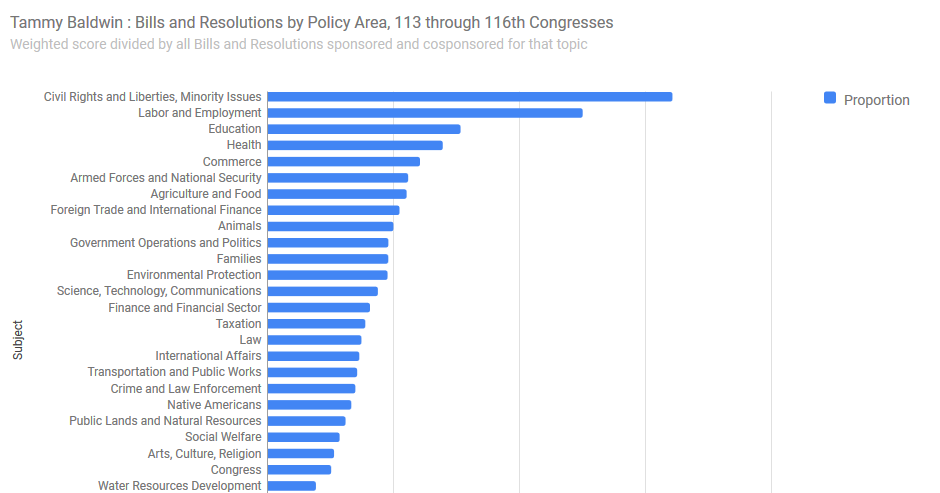
Again, you can double-check this sorting by clicking on the bars of the graph to see the measures in question.
– ❉ –
As seen in the July issue of JMLA...
Do use the PubMed Clinical Queries? If so, you should be aware that the “Broad” scope may not be as broad as one would like. Instead, there are many occasions when items that appear in a “Narrow” scoped search just don’t show up in their Broad counterpart. This is particularly true for Prognosis, where a searcher could easily miss one (presumably relevant) Prognosis/Narrow citation for every ten Prognosis/Broad citations retrieved.
Much more detail can be found in my new article, published in the most recent issue of JMLA:
Sperr, Edwin Vincent Jr. “Mind the gap: identifying what is missed when searching only the broad scope with clinical queries.” Journal of the Medical Library Association : JMLA vol. 107,3 (2019): 333-340. doi:10.5195/jmla.2019.589
– ❉ –
Introducing PubTrees
Introducing PubTrees, an interface for searching PubMed that visually reveals the textual relationships within the results of that search.
PubTrees is based upon the Word Tree visualization technique first developed by Wattenberg and Viégas in 2007. Similarly to word (or “tag”) clouds, word trees show the relative frequency of terms in a text. Where they are unique is that they also show the contexts in which those terms are used.
For example, if we get a little meta and search the term “PubMed” in PubMed, we’ll quickly surmise that when folks write about using PubMed, they are most often discussing it in the context of other databases…
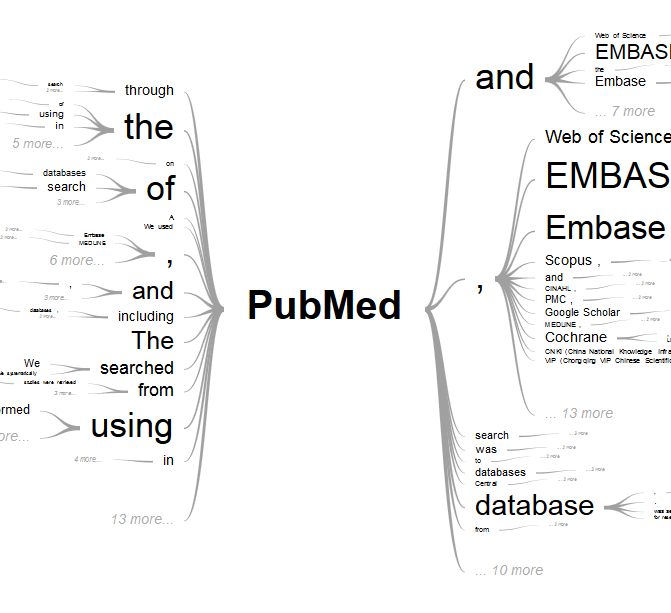 …thus illustrating the power of this technique as we quickly summarize 100 different citations and gain some sense of what the underlying articles might be talking about.
…thus illustrating the power of this technique as we quickly summarize 100 different citations and gain some sense of what the underlying articles might be talking about.
PubTrees works by using the NCBI E-utils API to run your search against PubMed and then extracting the titles and abstracts for the first 50, 100 or 150 citations returned. Those bits of text are combined into a big blob which is then visualized using the implementation of Word Trees found at Google Charts.
On the user end, first you compose a PubMed search (as simple or as complex as need be). Then once PubTrees completes that search you choose a “root” word to center your tree upon. Note – you can use any single word you like, though some words will give more useful results than others. You can also redraw the tree by either changing the number of citations that are graphed or by selecting a different root.
Crucially, you can take advantage of the *interactive* nature of Google Charts Word Trees to dig deeper into a tree once you draw it. For example, one could begin with a search for "morphine" and see that "equivalents" is a common succeeding term.
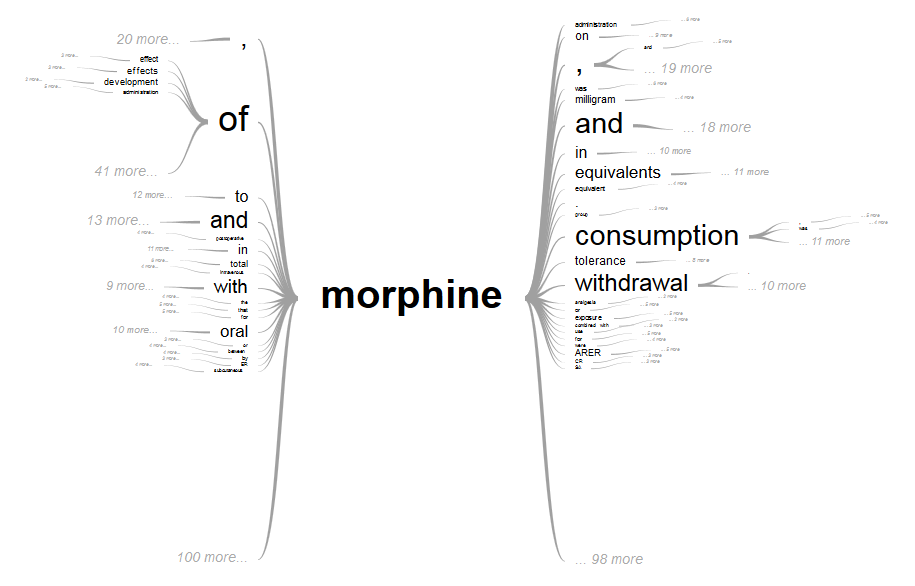
Clicking on that will redraw the tree and show that in that context, the term of art "MME" is especially important.

It’s early days, but I think this technique has a lot of potential to allow users to quickly drill down to new terms of art and relationships between concepts as they begin their search. Let me know what you think!
– ❉ –
I went to Madison
A few weeks ago I was given the opportunity to present at the Spring 2019 meeting of the Georgia Health Sciences Library Association in lovely Madison, Georgia. It was a great chance to chat with my medical librarian colleagues, and I’m always eager to talk about Search Workbench. If you wander over to the UGA IR, you’ll find my slides for “Beyond the List: Refining your PubMed searches with interactive visualizations”.
– ❉ –