Introducing PubTrees
Introducing PubTrees, an interface for searching PubMed that visually reveals the textual relationships within the results of that search.
PubTrees is based upon the Word Tree visualization technique first developed by Wattenberg and Viégas in 2007. Similarly to word (or “tag”) clouds, word trees show the relative frequency of terms in a text. Where they are unique is that they also show the contexts in which those terms are used.
For example, if we get a little meta and search the term “PubMed” in PubMed, we’ll quickly surmise that when folks write about using PubMed, they are most often discussing it in the context of other databases…
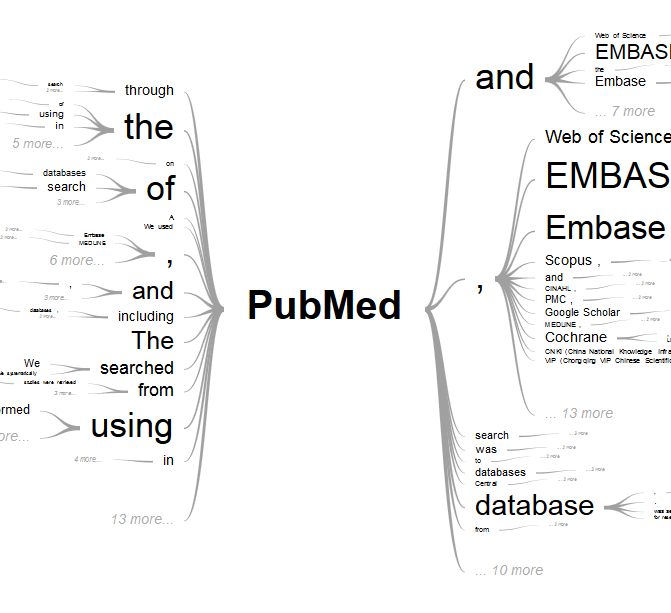 …thus illustrating the power of this technique as we quickly summarize 100 different citations and gain some sense of what the underlying articles might be talking about.
…thus illustrating the power of this technique as we quickly summarize 100 different citations and gain some sense of what the underlying articles might be talking about.
PubTrees works by using the NCBI E-utils API to run your search against PubMed and then extracting the titles and abstracts for the first 50, 100 or 150 citations returned. Those bits of text are combined into a big blob which is then visualized using the implementation of Word Trees found at Google Charts.
On the user end, first you compose a PubMed search (as simple or as complex as need be). Then once PubTrees completes that search you choose a “root” word to center your tree upon. Note – you can use any single word you like, though some words will give more useful results than others. You can also redraw the tree by either changing the number of citations that are graphed or by selecting a different root.
Crucially, you can take advantage of the *interactive* nature of Google Charts Word Trees to dig deeper into a tree once you draw it. For example, one could begin with a search for "morphine" and see that "equivalents" is a common succeeding term.
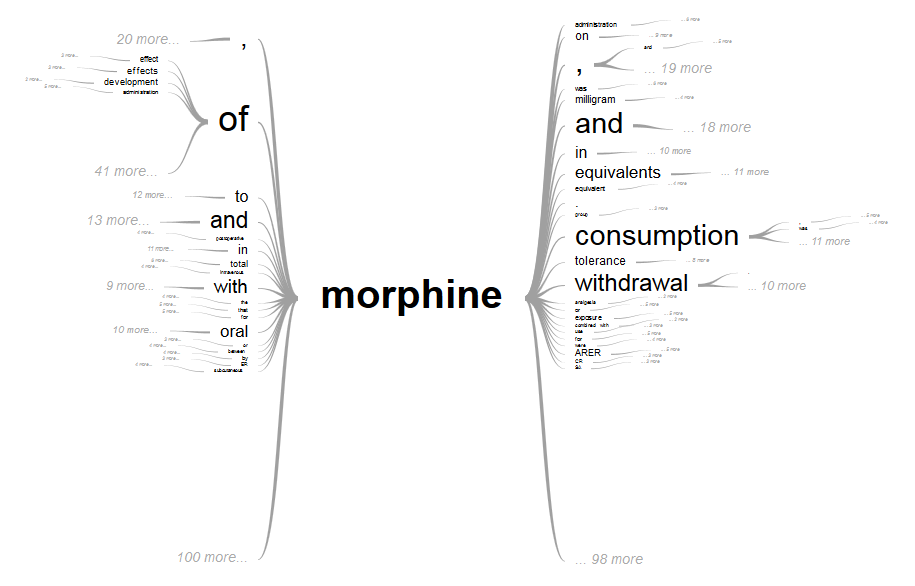
Clicking on that will redraw the tree and show that in that context, the term of art "MME" is especially important.

It’s early days, but I think this technique has a lot of potential to allow users to quickly drill down to new terms of art and relationships between concepts as they begin their search. Let me know what you think!