Posts
Updating News in Proportion
I’ve made a couple of updates to my project News in Proportion. As before, this application renders a search of the items in Chronicling America into a choropleth map showing the relative proportion of results for each state. However, due to an increase of content in Chronicling America, it now covers a couple of states that it did not before: Maine, New Jersey and Wyoming. After closer examination, I also decided to remove Massachusetts from the counts – at the moment, only one (partially) Massachusetts newspaper is included in Chronicling America (the Cronaca sovversiva), and the bulk of its text is in Italian.
Beyond that, I’ve removed the option to render raw counts (as opposed to proportions). Mapping raw counts either ends up swallowing up effects due to the differences in the total number of ChronAm pages per state, or it ends up being pretty much the same map as the proportional one. I’ve also made a couple of UI tweaks.
As always, let me know if you have any comments, questions or brickbats…
– ❉ –
Trends in COVID-19 Publications
The recent emergence of COVID-19 has led to a flood of publications about it (as well as SARS-CoV-2) in the biomedical literature. Indeed, items found with the PubMed term “COVID-19” (which is still probably the best single term to use have gone from nothing a year ago to a bit over 4.5% of all PubMed citations for 2020.
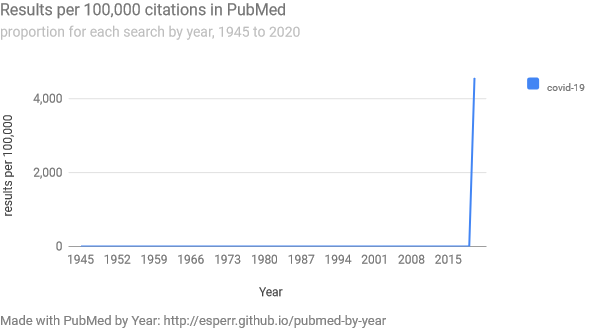
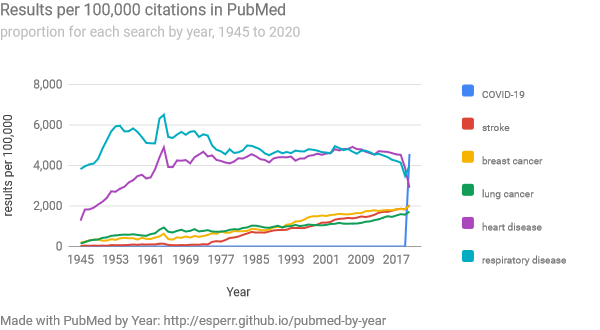
If there is any question of how significant that number is, note that this is well higher than the yearly rate for stroke, breast cancer or lung cancer. COVID-19 cites are now in the same neighborhood as those for heart and respiratory diseases.
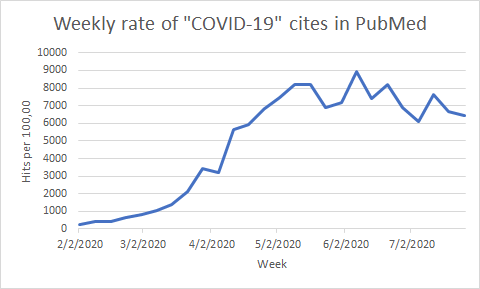
Of course, a yearly average is just that – it might be difficult to truly get a sense of this onslaught when we’re averaging June and July together with February, when COVID-19 items were (relatively) sparse. If instead, we search on the PubMed record creation date and take the proportion of COVID-19 items created in a given week to the rest of PubMed, we get a more granular view of what’s going on. Now we can see that production peaked (so far) in early June, when COVID-19 items made up nearly 9% of the total.
Of course, medical librarians and other experienced PubMed users will know that full indexing of items for MEDLINE takes time. If we compare all COVID-19 items to those that are in the “medline” subset, we see that many items (particularly the most recent) have yet to be indexed.
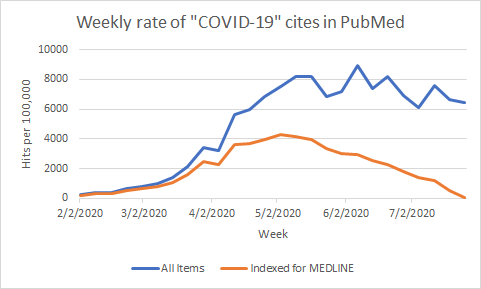
This has serious ramifications for the construction of PubMed search strategies, as medical subject headings can’t be used to find unindexed items.
– ❉ –
Testing the PubMed Search Tester
As I mentioned earlier, I’ve refined the user interface for the PubMed Search Tester, an application designed to facilitate the process of refining a complex strategy by allowing you to automatically compare different search variants against a validation set of “known-good” items.
Of course, the utility of this approach is contingent on whether the relatively small validation sets generated by the Search Tester are large enough to reliably discriminate between different search strategies. I cordially invite you to participate in a research study (UGA IRB ID# PROJECT00001362) to test whether this is the case.
If you agree to take part in this study, you will be directed to a specially modified version of PubMed Search Tester where you’ll find a clinical question as well as a rubric for evaluating which MEDLINE citations might contain the answer to that question. Armed with that rubric, you will evaluate a series of randomly selected citations from a predetermined search strategy and decide whether each citation is a “Good” citation that might answer that question or a “Bad” one that probably would not. Once you complete a question, your choices will be recorded, and you will have the option to continue to another. Each question should take around 10 minutes to complete. If you agree to participate, please begin by reviewing the formal Consent Agreement. Then start with a very short demographic questionnaire before you continue on to the questions.
Thanks for your help!
– ❉ –
(Re)introducing the PubMed Search Tester
I have made some significant changes to an application that I first introduced at MLA 2019. This app, the PubMed Search Tester, is designed to facilitate the process of refining a complex strategy by allowing you to compare search variants against a vaidation set.
When composing a hedge or systematic review search, it’s common to test different strategies against a “validation set” of cites that you know are good. Such validation sets are typically constructed by looking at items found in a systematic review or by hand-searching a collection of core journals in a particular field. This approach yields reliable results, but can also be cumbersome and time consuming.
PubMed Search Tester streamlines this process. It runs an initial search and then shows you a random selection of what PubMed has found. Pick the citations that match what you’re looking for (and reject the ones that don’t), and those “Good” citations are added to a new validation set.
Once your validation set is big enough to be a reliable one, you can use PubMed search tester to automatically compare new iterations of your search strategy against it. Values for precision and sensitivity are then computed (according to the formula set out in Agoritsas, et al.) and shown for each one.
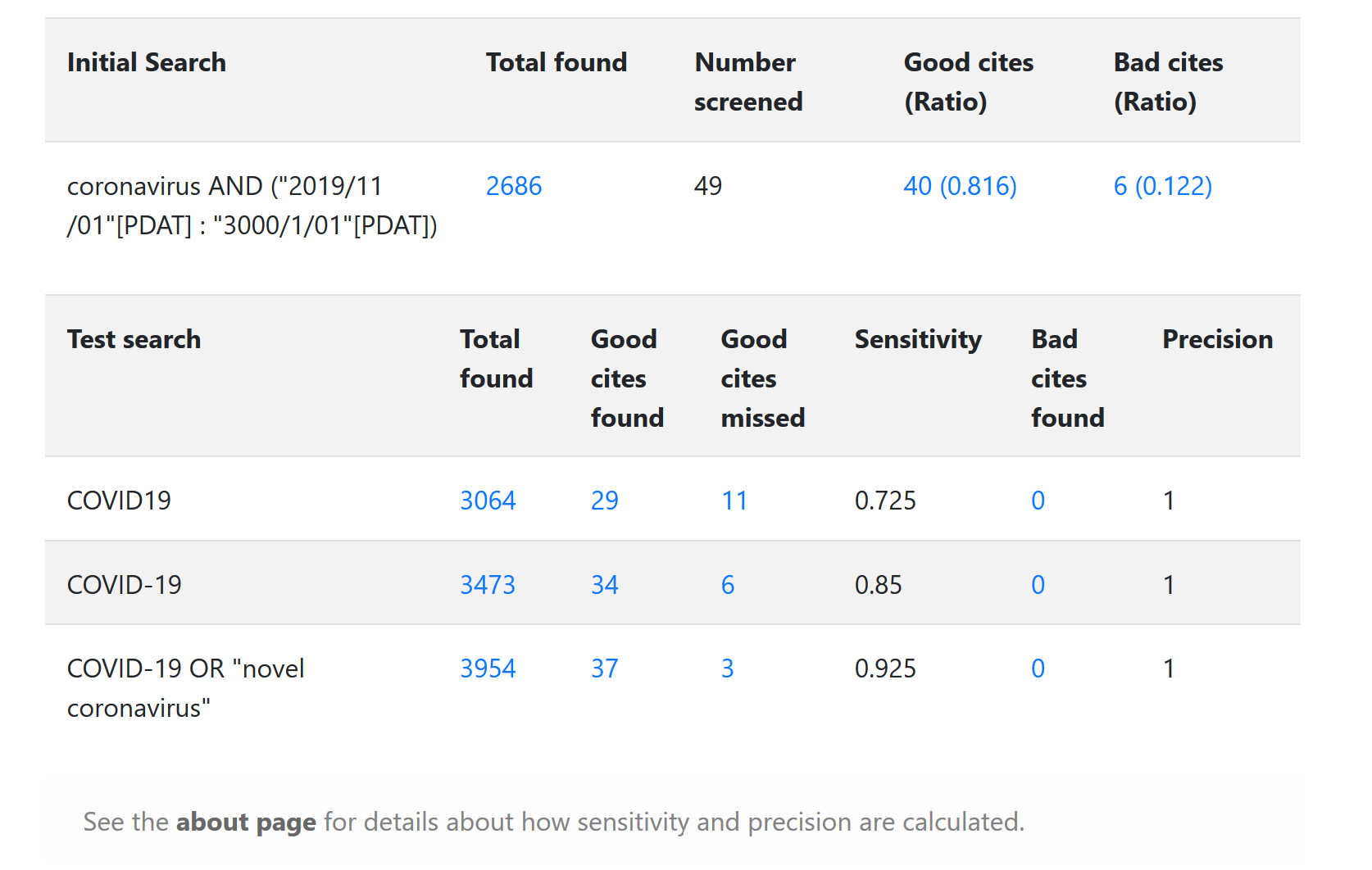
For example, if we wanted to test a couple of different simple strategies for #COVID19, we might start by using the very broad search “coronavirus AND (“2019/11/01”[PDAT] : “3000/1/01”[PDAT])” This gets us mostly relevant stuff, but a couple of off-target results as well. Once we’ve finished sorting, we have items in the “Good”, “Bad” and “Skipped” piles:

Once we have our set of “Good” items, we can start testing different approaches in earnest. In this case, we can verify that “COVID-19” works better than “COVID19” as a search term. We can also see that ORing “COVID-19” together with “novel coronavirus” is the most sensitive of the three strategies tested:
I think that this application will be useful for medical librarians or anyone else that finds themselves having to determine the best combination of precision and sensitivity for a complex PubMed search. There are still some things to figure out, however, not least the question of how representative random samples of PubMed results are of the results for a search as a whole.
Watch this space, as this is a question that I am actively attempting to figure out. And soon, you will have the opportunity to help!
In the meantime, be sure and check out the PubMed Search Tester for yourself and see what you think…
– ❉ –
Covid vs Covid
Medical Librarians and other folks who search PubMed on a regular basis are likely familiar with the process of Automated Term Mapping, where PubMed takes your search terms and “translates” them into different synonyms, variants and Medical Subject Headings. This process is often extremely helpful, but it does mean that small differences in the wording of your search can have big impacts on what it retrieves.
This can be seen clearly when comparing the two search terms “Covid19” and “Covid-19”. (view on PubVenn)
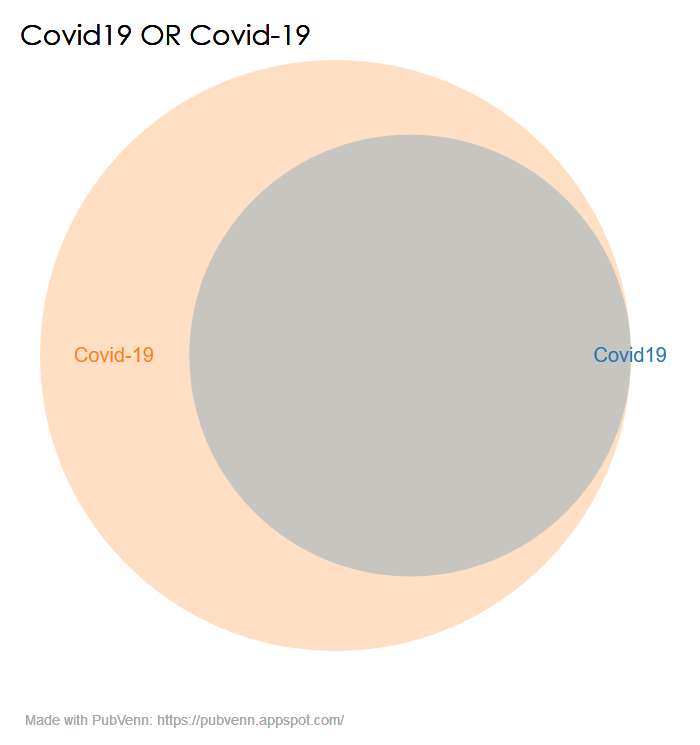
Why the difference? In the first case, ATM in Legacy PubMed is rendering “Covid19” as
“COVID-19”[Supplementary Concept] OR “COVID-19”[All Fields] OR “covid19”[All Fields]
…while in the second, “Covid-19” becomes (at least as of today)
“COVID-19”[All Fields] OR “severe acute respiratory syndrome coronavirus 2”[Supplementary Concept] OR “severe acute respiratory syndrome coronavirus 2”[All Fields] OR “2019-nCoV”[All Fields] OR “SARS-CoV-2”[All Fields] OR “2019nCoV”[All Fields] OR ((“Wuhan”[All Fields] AND (“coronavirus”[MeSH Terms] OR “coronavirus”[All Fields])) AND 2019/12[PDAT] : 2030[PDAT])
The “as of today” caveat is an important one. The National Library of Medicine has made clear that ATM mappings are subject to change and should not be regarded as immutable (or reproducible over time). With “Covid-19”, it looks as if the mapping includes not only ‘typical’ translations, but the NLM’s suggested interim search strategy as well.
As always, if you’re trying to put together a complicated search, consider using a tool like Search Workbench to validate it.
– ❉ –