(Re)introducing the PubMed Search Tester
I have made some significant changes to an application that I first introduced at MLA 2019. This app, the PubMed Search Tester, is designed to facilitate the process of refining a complex strategy by allowing you to compare search variants against a vaidation set.
When composing a hedge or systematic review search, it’s common to test different strategies against a “validation set” of cites that you know are good. Such validation sets are typically constructed by looking at items found in a systematic review or by hand-searching a collection of core journals in a particular field. This approach yields reliable results, but can also be cumbersome and time consuming.
PubMed Search Tester streamlines this process. It runs an initial search and then shows you a random selection of what PubMed has found. Pick the citations that match what you’re looking for (and reject the ones that don’t), and those “Good” citations are added to a new validation set.
Once your validation set is big enough to be a reliable one, you can use PubMed search tester to automatically compare new iterations of your search strategy against it. Values for precision and sensitivity are then computed (according to the formula set out in Agoritsas, et al.) and shown for each one.
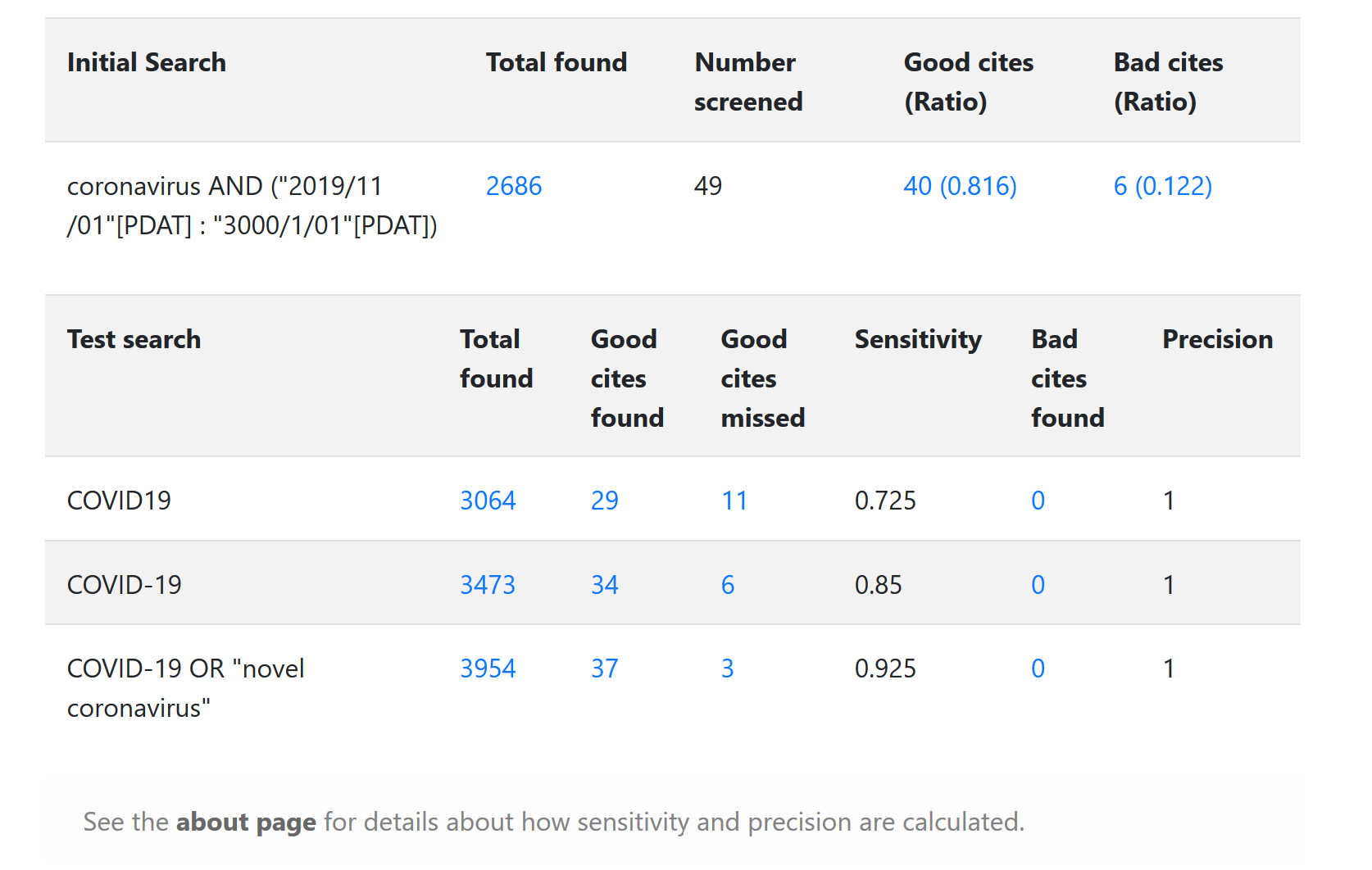
For example, if we wanted to test a couple of different simple strategies for #COVID19, we might start by using the very broad search “coronavirus AND (“2019/11/01”[PDAT] : “3000/1/01”[PDAT])” This gets us mostly relevant stuff, but a couple of off-target results as well. Once we’ve finished sorting, we have items in the “Good”, “Bad” and “Skipped” piles:

Once we have our set of “Good” items, we can start testing different approaches in earnest. In this case, we can verify that “COVID-19” works better than “COVID19” as a search term. We can also see that ORing “COVID-19” together with “novel coronavirus” is the most sensitive of the three strategies tested:
I think that this application will be useful for medical librarians or anyone else that finds themselves having to determine the best combination of precision and sensitivity for a complex PubMed search. There are still some things to figure out, however, not least the question of how representative random samples of PubMed results are of the results for a search as a whole.
Watch this space, as this is a question that I am actively attempting to figure out. And soon, you will have the opportunity to help!
In the meantime, be sure and check out the PubMed Search Tester for yourself and see what you think…