Introducing Committee Flow
I’ve put together a couple of new applications in response to the Library of Congress-sponsored Congressional Data Competition. The remit for this was to “…leverage that data to create new meaning or tools to help members of Congress and the public explore it in new ways.”
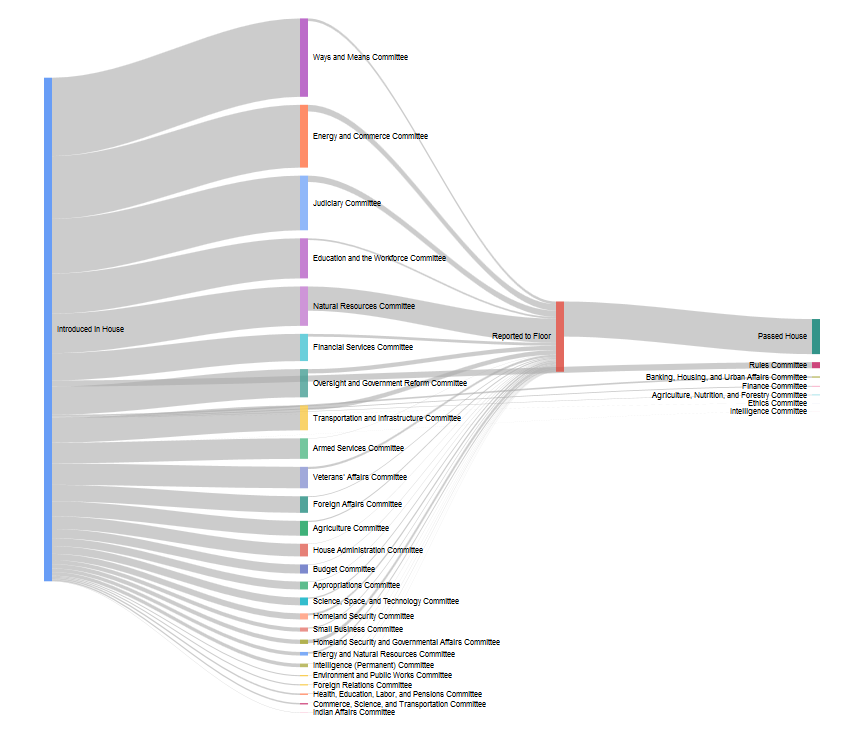
After spending a lot of time looking at the XML files at the GPO’s Bulk Data Bill Status page, I thought that one approach would be to do something that reflects the winding path a bill (or resolution) wends on its way from introduction to passage. It felt like a good opportunity to use a Sankey diagram, so after some poking around to make sure that nobody else had already done this with US Congressional data, I started work on Committee Flow.
The underlying architecture is fairly simple. In Google Charts, Sankey diagrams are built by defining a series of connections between points and their accompanying weights, a la
[ 'A', 'X', 5 ],
[ 'A', 'Y', 7 ],
[ 'A', 'Z', 6 ],
[ 'B', 'X', 2 ]...
Since each bill status record details which committee a bill was initially assigned to after introduction, as well as telling us whether it made it out of committee, we can count all of those connections progammatically. We can also glean whether that bill eventually passed on the floor. By summing all those counts together, we can can say that x number of bills were sent to Finance in a congress, while y were reported out and so build our diagram.
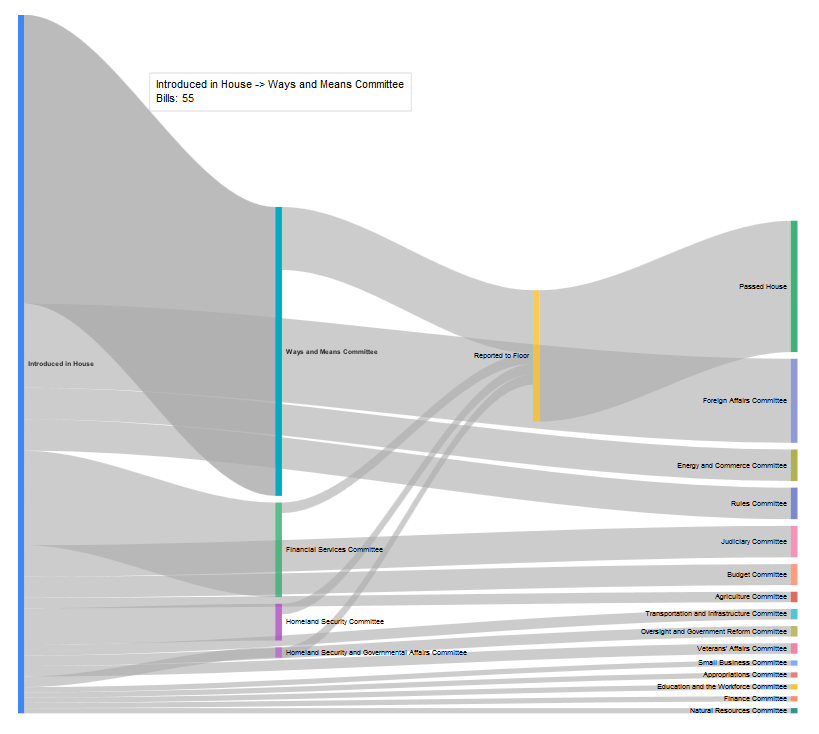
Notably, since each bill and resolution is also tagged with the policy area and legislative subject headings that it is indexed under, we can also do counts for bills about individual topics. For instance, the policy areas “Foreign Trade and International Finance”:
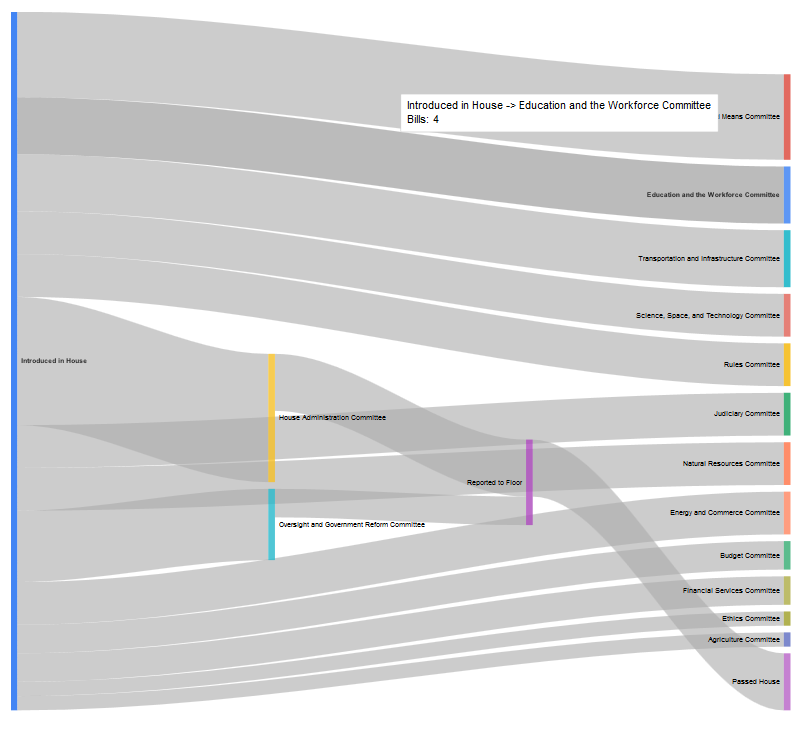
…or the legislative subjects “Libraries and archives”:
All the initial counting is handled by a Python script that slurps up the individual XML status files from a given directory. It’s kinda primitive, so make sure that you have only one type of status (H.R., H.Res., S. or S.Res) and one congress in each directory you are scanning. Once you have your resulting files (“sankeysubjects_114_S.js”, etc.), dump them into the designated /data directory, and you’re good to go.